Automated Learning From Man Pages
EuroBSDCon 2016, Belgrade
Abhinav Upadhyay
About myself
- Implemented NetBSD's apropos(1) in 2011
- Recently got commit bit to NetBSD
- Working on improving apropos(1) and related tools
- Also created https://man-k.org
Learning to Rank
- Search in NetBSD's apropos(1)
- How does it work?
- What is Machine Learning
- How can Machine Learning help?
- Results
netbsd's apropos(1)
- Full text search instead of just searching the title
- Uses mandoc(3) to parse the man pages
- Uses Sqlite to create the full text index
$apropos ls
intro(9) - introduction to kernel internals
rump(7) - The Anykernel and Rump Kernels
NLS(7) - Native Language Support Overview
usermgmt.conf(5) - user management tools configuration file
shells(5) - shell database
protocols(5) - protocol name data base
pkg_install.conf(5) - configuration file for package installation tools
uslsa(4) - USB support for Silicon Labs CP210x series serial adapters
mpt(4) - LSI Fusion-MPT SCSI/Fibre Channel driver
mpls(4) - Multiprotocol Label Switching
$apropos ls
ls (1) list directory contents
nslookup (8) query Internet name servers interactively
curses_border (3) curses border drawing routines
column (1) columnate lists
dmctl (8) manipulate device-mapper driver command
getbsize (3) get user block size
chflags (1) change file flags
symlink (7) symbolic link handling
string_to_flags (3) Stat flags parsing and printing functions
stat (1) display file status
Old apropos(1) output
New apropos(1) output
$apropos "how to compare two strings"
how to compare two strings: nothing appropriate$apropos "how to compare two strings"
strcmp (3) compare strings
memcmp (9) compare byte string
memcmp (3) compare byte string
bcmp (3) compare byte string
bcmp (9) compare byte string
ldapcompare (1) LDAP compare tool
strcasecmp (3) compare strings, ignoring case
wcscasecmp (3) compare wide-character strings, ignoring case
msgcmp (1) compare message catalog and template
strcoll (3) compare strings according to current collation
Old apropos(1) output
New apropos(1) output
How it Works: A quick Detour
- Parse Man pages
- Tokenize
- Stem
- Store
The Database Structure
| Column | Weight |
|---|---|
| name | 2.0 |
| name_desc | 2.0 |
| description | 0.55 |
| library | 0.10 |
| return values | 0.001 |
| environment | 0.20 |
| files | 0.01 |
| exit status | 0.001 |
| diagnostics | 2.0 |
| errors | 0.05 |
| machine | 1.0 |
The Ranking Algorithm
Require: User query q
Require: Document d whose weight needs to be computed
1: tf ← 0.0
2: idf ← 0.0
3: k ← 3.5
4: doclen ← length of the current document
5: ndoc ← Total number of documents in the corpus
6: for each term t in q do:
7: for each column c in the FTS index do:
8: nhitcount ← Frequency of term t in column c in current document
9: nglobalhitcount ← Frequency of term t in column c in all documents
10: ndocshitcount ← Number of documents in which t occurs in c at least once
11: w ← weights[c]
12: idf ← comput_idf_for_term(t, w)
13: tf ← tf + compute_tf_for_term(t, w)
14: score ← tf * idf / (k + tf)
15: return scoreWhat's the problem
- Weights are arbitrarily chosen
- Not easy to try out different ranking schemes
What is machine learning?
how does it help?
Machine learning
Field of study that gives computers the ability to learn without being explicitly programmed
Types of machine learning algorithms
Types of machine learning algorithms
- Supervised Machine Learning
Types of machine learning algorithms
- Supervised Machine Learning
- Unsupervised Machine Learning
Types of machine learning algorithms
- Supervised Machine Learning
- Unsupervised Machine Learning
- Reinforcement Learning
Supervised Machine Learning
Regression Problems - Predicting a continuous value, e.g. temperature, stock prices.
Classification Problems - Predicting from a discrete set of possible outcomes, e.g. is it a dog or cat in the picture, is the tumor cancerous or benign.
Understanding Linear Regression
| Area (sqft.) | Price ($) |
|---|---|
| 500 | 14375 |
| 937 | 22540 |
| 1375 | 26220 |
| 1812 | 31360 |
| 2250 | 42535 |
| 2687 | 46195 |
| 3125 | 54060 |
| 3562 | 61540 |
| 4000 | 67700 |
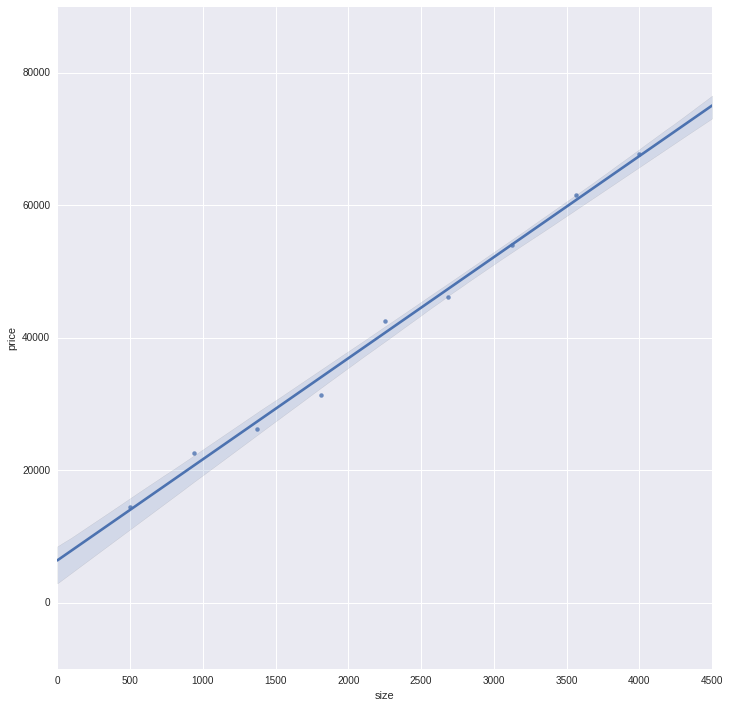
Understanding Linear Regression
Hypothesis:
Understanding Linear Regression
Hypothesis:
Understanding Linear Regression
Hypothesis:
w is the parameter for the model and x is the input
Ranking as a regression problem
Weight for column c
Term frequency for column c
Inverse document frequency for column c
Results of ranking as regression
- Semi-automatically generated a small data set of 850 odd records from the logs of man-k.org
Results of ranking as regression
- Semi-automatically generated a small data set of 850 odd records from the logs of man-k.org
- A regression model like Random Forest Obtains an accuracy of ~74% with such small data
Results of ranking as regression
- Semi-automatically generated a small data set of 850 odd records from the logs of man-k.org
- A regression model like Random Forest Obtains an accuracy of ~74% with such small data
- With more data, the results will get better
- Data available on https://github.com/abhinav-upadhyay/man-nlp-experiments/
$apropos -n 10 -C fork
fork (2) create a new process
perlfork (1) Perls fork() emulation
cpu_lwp_fork (9) finish a fork operation
pthread_atfork (3) register handlers to be called when process forks
rlogind (8) remote login server
rshd (8) remote shell server
rexecd (8) remote execution server
script (1) make typescript of terminal session
moncontrol (3) control execution profile
vfork (2) spawn new process in a virtual memory efficient wayWith old weights
With new weights
apropos -n 10 -C fork
fork (2) create a new process
perlfork (1) Perls fork() emulation
cpu_lwp_fork (9) finish a fork operation
pthread_atfork (3) register handlers to be called when process forks
vfork (2) spawn new process in a virtual memory efficient way
clone (2) spawn new process with options
daemon (3) run in the background
script (1) make typescript of terminal session
openpty (3) tty utility functions
rlogind (8) remote login serverapropos -n 10 create new process
init (8) process control initialization
fork (2) create a new process
fork1 (9) create a new process
timer_create (2) create a per-process timer
getpgrp (2) get process group
supfilesrv (8) sup server processes
posix_spawn (3) spawn a process
master (8) Postfix master process
popen (3) process I/O
_lwp_create (2) create a new light-weight process
With old weights
With new weights
apropos -n 10 create new process
fork (2) create a new process
fork1 (9) create a new process
_lwp_create (2) create a new light-weight process
pthread_create (3) create a new thread
clone (2) spawn new process with options
timer_create (2) create a per-process timer
UI_new (3) New User Interface
init (8) process control initialization
posix_spawn (3) spawn a process
master (8) Postfix master process
apropos -n 10 -C remove packages #old weights
groff_mdoc (7) reference for groffs mdoc implementation
pkg_add (1) a utility for installing and upgrading software package distributions
pkg_create (1) a utility for creating software package distributions
pkg_delete (1) a utility for deleting previously installed software package distributions
deroff (1) remove nroff/troff, eqn, pic and tbl constructs
pkg_admin (1) perform various administrative tasks to the pkg system
groff_tmac (5) macro files in the roff typesetting system
ci (1) check in RCS revisions
update-binfmts (8) maintain registry of executable binary formats
rpc_svc_reg (3) library routines for registering serversWith old weights
With new weights
apropos -n 10 -C remove packages
pkg_create (1) a utility for creating software package distributions
pkg_add (1) a utility for installing and upgrading software package distributions
pkg_delete (1) a utility for deleting previously installed software package distributions
deroff (1) remove nroff/troff, eqn, pic and tbl constructs
groff_mdoc (7) reference for groffs mdoc implementation
groff_tmac (5) macro files in the roff typesetting system
ci (1) check in RCS revisions
pkg_admin (1) perform various administrative tasks to the pkg system
update-binfmts (8) maintain registry of executable binary formats
rpc_svc_reg (3) library routines for registering serverspkg_create moves to 1, pkg_delete moves up, I think pkg_admin should have been further up.
Ranking as a classification problem
Ranking as a classification problem
Treat it as a problem of classifying the results as "relevant" or "non-relevant" to the query
uNDERSTANDING CLASSIFICATION

Results of ranking as classification
- Hand labeled dataset of about 3000 data points
Results of ranking as classification
- Hand labeled dataset of about 3000 data points
- About 50% accuracy on the task of predicting relevance on a scale of 0-4
Results of ranking as classification
- Hand labeled dataset of about 3000 data points
- About 50% accuracy on the task of predicting relevance on a scale of 0-4
- About 70% accuracy on the task of predicting relevance on a scale of 0-2
Results of ranking as classification
- Hand labeled dataset of about 3000 data points
- About 50% accuracy on the task of predicting relevance on a scale of 0-4
- About 70% accuracy on the task of predicting relevance on a scale of 0-2
- About 80% accuracy when doing binary classification
- Data available on github, work in progress to add more data points.
Results of ranking as classification
- Hand labeled dataset of about 3000 data points
- About 50% accuracy on the task of predicting relevance on a scale of 0-4
- About 70% accuracy on the task of predicting relevance on a scale of 0-2
- About 80% accuracy when doing binary classification
- Data available on github, work in progress to add more data points.
- Overall results for classification - not great so far, more data needed